
Picture this. It’s pouring rain, and you’re holding your umbrella for dear life. You’re coming out of the supermarket with a bag full of groceries. Your phone rings. How on earth can you pick up your phone and answer this (very poorly timed) call? With Bitey you can simply click your teeth to answer your call and have it routed to your earphones!

Bone conduction microphone used in Bitey.
Bitey is a system that can identify what teeth are you clicking and link actions to specific pairs of teeth. All you need to get started with Bitey is a bone conduction microphone (we used one of these throat microphones that security guards use, as seen in the picture), and a copy of our machine learning pipeline to identify teeth clicks.

One of our participants wearing a Bitey microphone.
Because we’re interested in how teeth clicks sound, the normal placement of this microphone (i.e., around the throat) is not ideal—there is a lot of stuff going on around there: muscles, fat, and all the stuff that helps you breathe and talk. We experimented on where to place this and found that the best location is right behind your ears: it is practically invisible (see picture on the left), and the sound is very clear, it uses your skull as a huge amplifier 🤯. Once wearing the microphone, before Bitey can identify your teeth clicks, there needs to be a (very quick) training phase. Here you discover what teeth clicks you can click reliably and comfortably, and record a short 10 second clip of you clicking each of them. With these recordings as a baseline for our simple machine learning algorithm, Bitey can then identify what teeth you’re clicking and map actions to specific clicks.
How does it work?
Let’s try something. Click your front teeth. Good, now click your back teeth. See how they sound different inside your head? This is the premise behind Bitey: if we can tell that our teeth make different sound inside our head, a computer should be able to do so too. The question then is, how can we identify them using a computer? The first step is to identify what useful information we can extract from the teeth-click recordings, as using the actual recording will not perform well. Here we turn to Fourier, and his transform function. In a nutshell, this function separates each of the frequencies that make up a sound (if you’d like to read more about it, check its Wikipedia article). This worked like a charm! Below is the result of running the Fourier transform for two different teeth clicks, and we can see that their frequency signature is clearly different from each other.
Right, so now that we extracted interesting information about the clicks, it’s time to teach a machine how to identify them. We make use of a (very simple) machine learning algorithm called Support Vector Machine. We chose this specific algorithm because it works well with data with many features (and as we see from the plot below we have 4000 of them!). We used the data recording in the training phase to train this algorithm, and we’re off to the races!
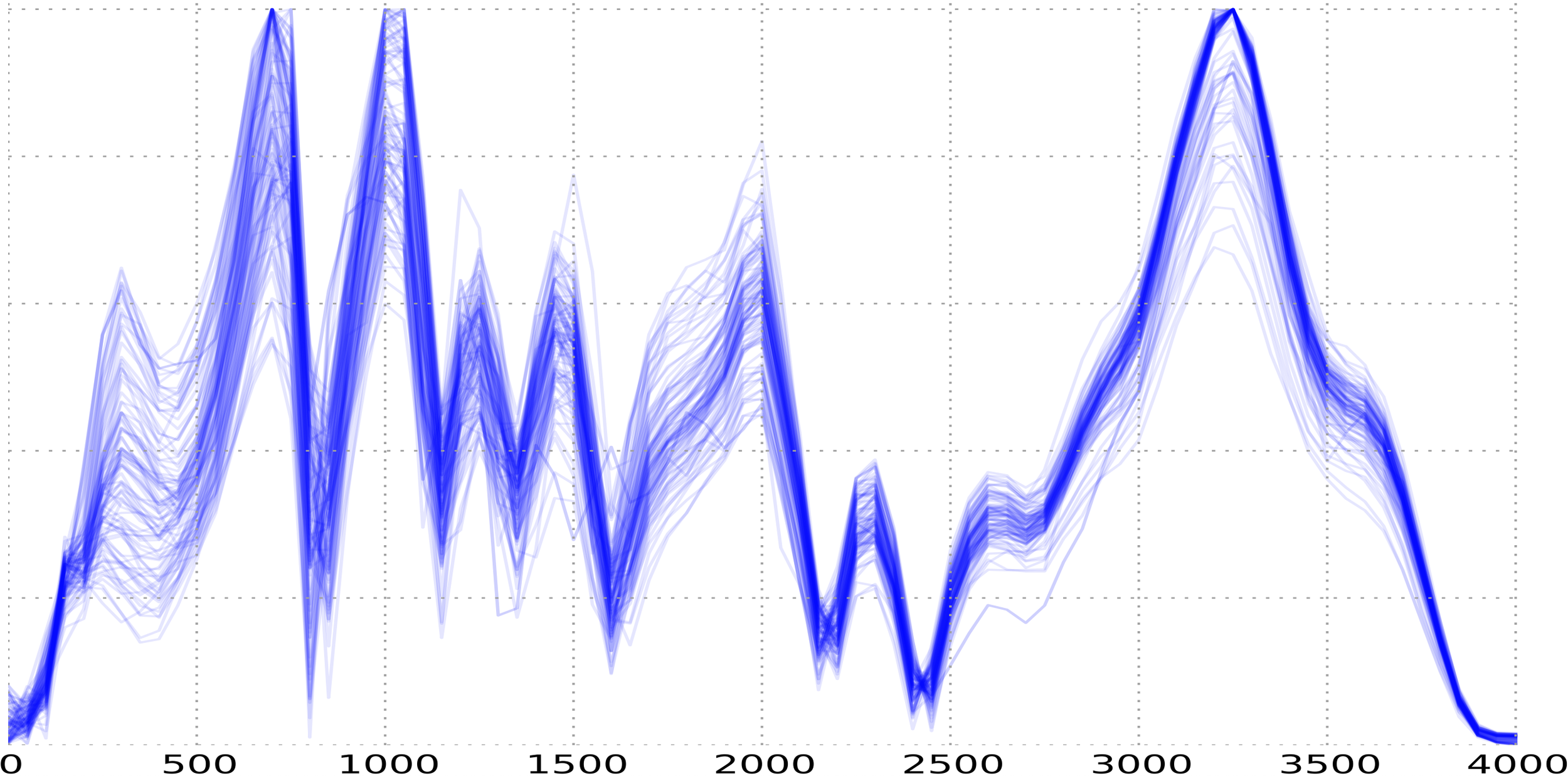
Result of a Fourier transform of 98 teeth clicks, overlaid over each other.

Result of a Fourier transform of 95 teeth clicks, overlaid over each other.
Some interesting considerations
Bitey works remarkably well in a variety of situations, however, during our research we found a series of interesting details that could affect its performance. One interesting finding was that minute changes in placement of our microphone affected (sometimes significantly) the performance of our system. In retrospective, this makes sense as the sound would take different paths to reach the microphone’s new location. To fix this we recommended in our paper that users should do a recalibration phase before each day: don the microphone and train a whole set of clicks, which should take less than two minutes. Also, we found that our system was very robust against external noise. Having the microphone clamped (it kinda hurt a bit, actually) to your head meant that not a lot of external noise would leak in. However, what would happen if you were actually using your teeth for, you know, eating? We tested this by wearing the microphone a full day and just doing normal daily stuff (e.g., walking, eating, etc). We found that, although we found a lot of “potential clicks”, our algorithm was robust enough to identify that these were noise and not process them. Last, we found that, unsurprisingly, we cannot train our system with data from one person and have another use it. This is fairly intuitive as our heads have a variety of shapes, and thus sound travels differently through them.
You can download this paper from the ACM Digital Library, or directly from this website.